Homework 10: File Structures, Indexing, and Query Optimization
This homework will develop your understanding of database indexes and query optimization.
Instructions
You may work either individually or with a partner.
Problem 1: Hash Index
A PARTS file with Part# as the hash key includes records with the following Part# values: 2369, 3760, 4692, 4871, 5659, 1821, 1074, 7115, 1620, 2428, 3943, 4750, 6975, 4981, 9208. The file uses eight buckets, numbered 0 to 7. Each bucket is one disk block and holds two records. Load these records into the file in the given order. Use the hash function h(K) = K mod 8. Use chaining for collision resolution.
- Draw the final contents of each bucket, using the notation shown in Figure 16.10
- Note: Your number of buckets and bucket size for this problem should differ from Figure 16.10
- Calculate the average number of block accesses for a random retrieval on Part#. Round to one decimal place.
- Note: You can assume that the table mapping bucket numbers to disk block addresses is already stored in memory (Figure 16.9). Thus, once you know the bucket number, retrieving the corresponding main bucket requires a single disk access.
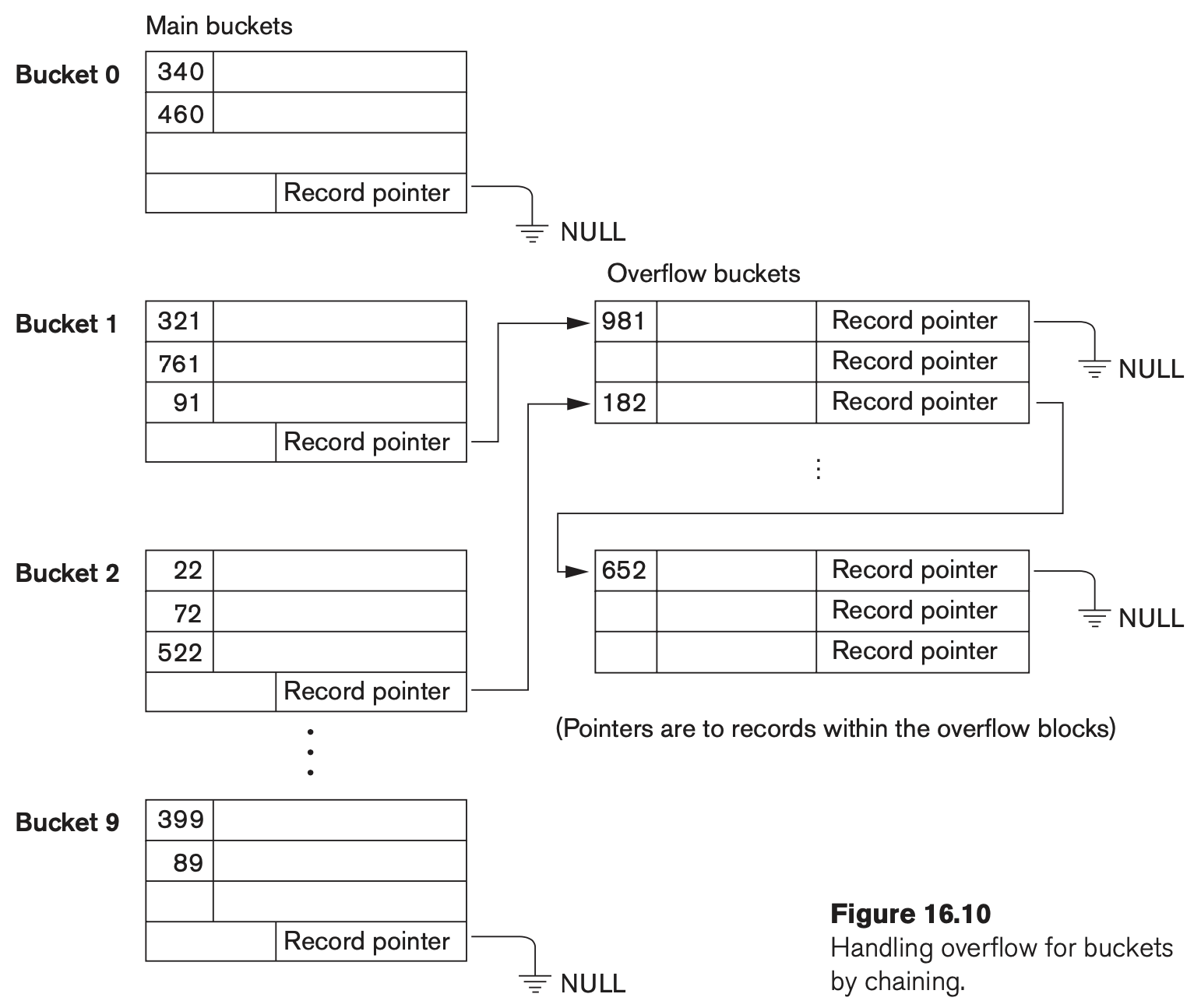
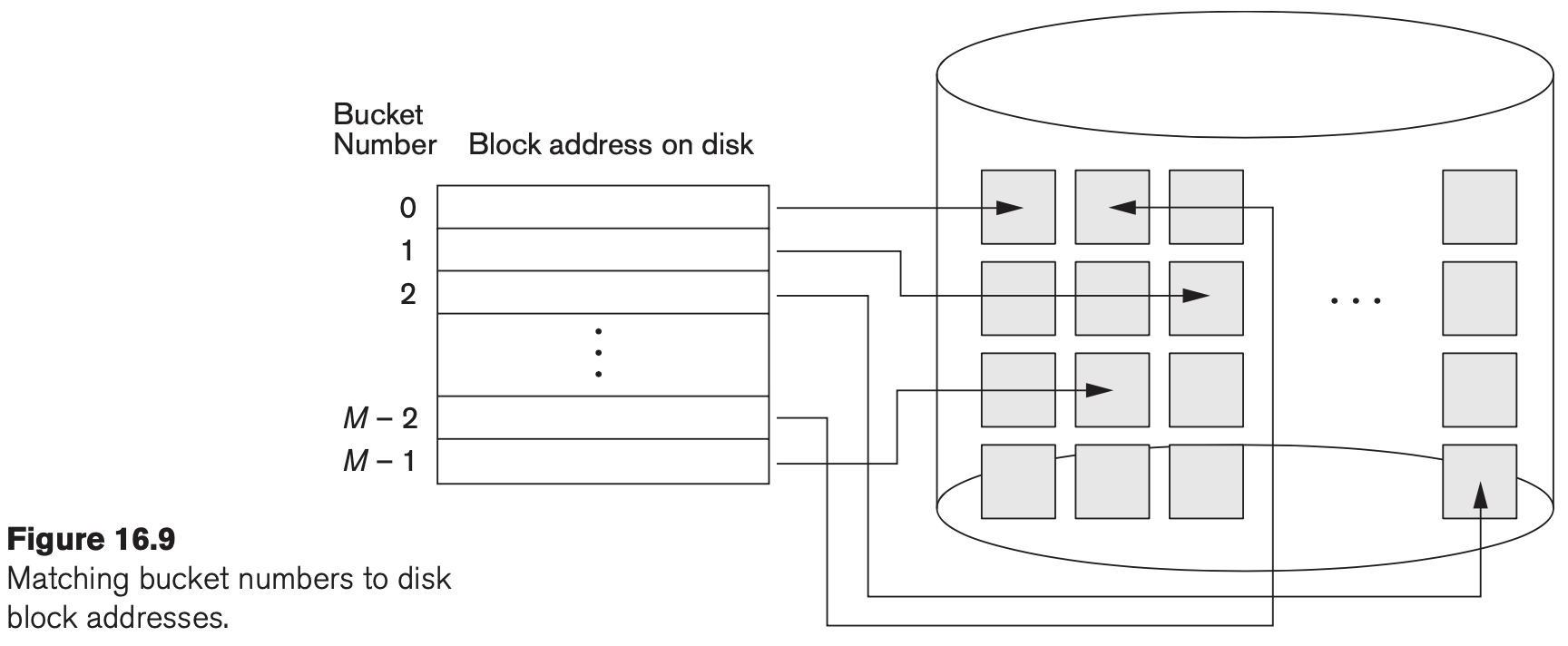
Problem 2: B+ Index
A PARTS file with Part# as the key field includes records with the following Part# values: 37, 60, 46, 48, 71, 59, 18, 10, 74, 15, 16, 20, 24, 43, 47, 50, 69, 8, 49, 33. Suppose that the search field values are inserted in the given order in a \(B^+\)-tree of order \(p = 4\) (each internal node can hold up to 4 search field values) and \(p_\text{leaf} = 3\) (each leaf node can hold up to 3 search field values).
- Show what the final tree will look like, using the notation below
- Assume each tree and leaf node is stored on a different block. How many block accesses are needed to:
- Locate the data pointer corresponding to the value
60? - Locate the data pointers corresponding to values
20to50?
- Locate the data pointer corresponding to the value
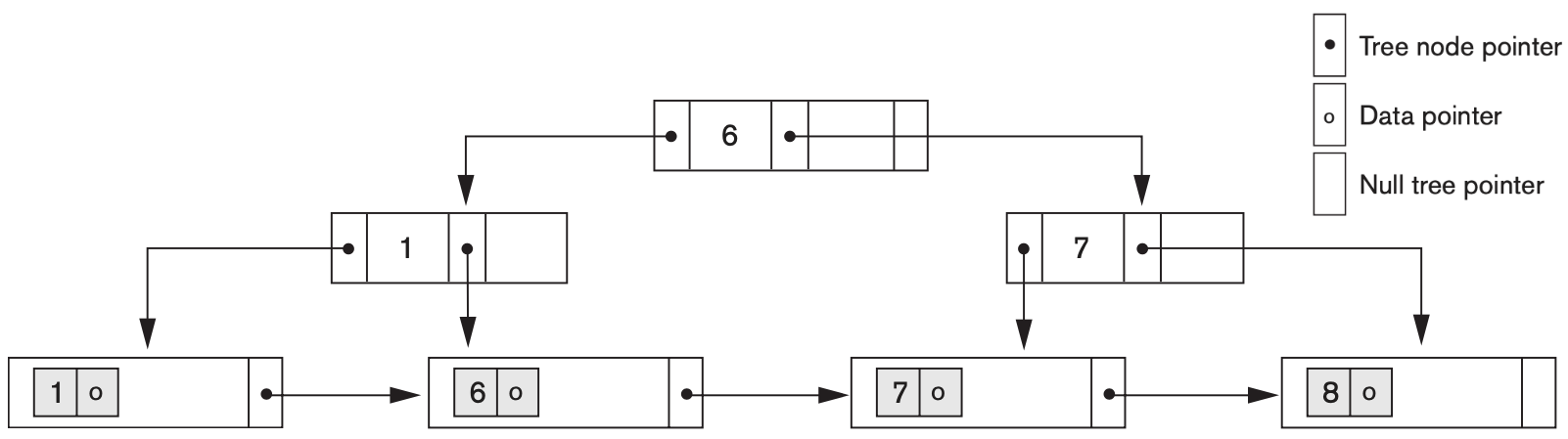
You may also find it helpful to refer to Figure 17.12 in the textbook.
Problem 3: Query Optimization
Consider the following query on the depicted schema:
SELECT instructor, student_id
FROM enrolled JOIN course ON course_num = number
JOIN teaches ON c_number = number

This query could be evaluated using the execution plan:
\[\pi_\text{instructor, student_id} \big( \sigma_\text{course_num = number AND c_number = number} ( \text{ENROLLED} \times \text{COURSE} \times \text{TEACHES} ) \big)\]The database has the following table and column statistics:
| Table | \(n_r\) | \(l_r\) |
|---|---|---|
| student | 5,000 | 58 bytes |
| enrolled | 20,000 | 16 bytes |
| course | 500 | 98 bytes |
| teaches | 700 | 58 bytes |
| V(A, r) |
|---|
| V(id, student) = 5,000 |
| V(student_id, enrolled) = 4,500 |
| V(course_num, enrolled) = 480 |
| V(number, course) = 500 |
| V(c_number, teaches) = 500 |
- Calculate the number of rows generated by the inefficient plan’s cross product
- Calculate the size (in bytes) of the intermediate table generated by the inefficient plan’s cross product
- Hint: Multiply the number of rows by the size of each row
- A more efficient plan would use natural joins instead of a cross product. Based on the statistics, which tables should be joined first, to have fewest number of rows in the intermediate table?
- For the most efficient plan, estimate the number of rows in the intermediate table
Submit
Submit your responses on Gradescope.