Eight Puzzle Problem Sets
Eight Puzzle (Part V)
100 points; pair-optional
-
The coding part described here should be submitted with Part IV PS19 By Saturday November 18, 2023
-
The Juputer Notebook report in Part V should be submitted as Problem Set 20 by 10:00 p.m. EDT on Tuesday, November 21, 2023
Important: This assignment builds on partIV
Part V: Compare algorithms, and try to speed things up!
In this last part of the eight puzzle, you will write code to facilitate the comparison of the different state-space search algorithms, and you will also attempt to speed things up so that your code can more easily solve puzzles that require many moves.
Finally, you will report the results of your experiments in a Jupyter Notebook.
Your tasks
-
In
eight_puzzle.py, write a function namedprocess_file(filename, algorithm, depth_limit = -1, heuristic = None). It should take the following four inputs:-
a string
filenamespecifying the name of a text file in which each line is a digit string for an eight puzzle. For example, here is a sample file containing 10 digit strings, each of which represents an eight puzzle that can be solved in 10 moves: 10_moves.txt -
a string
algorithmthat specifies which state-space search algorithm should be used to solve the puzzles ('random','BFS','DFS','Greedy', or'A*') -
an integer
depth_limitthat can be used to specify an optional parameter for the depth limit -
an optional parameter
heuristic, which will be used to pass in a reference to the heuristic function to use.
To make the third and fourth parameters optional, you should use the following function header:
def process_file(filename, algorithm, depth_limit=-1, heuristic=None): """ doctring goes here """
Note that this header specifies a default value of
-1for the inputdepth_limit, which is why this input is optional. If we leave it out (by only specifying two inputs when we call the function), Python will givedepth_limitits default value of-1. If we specify a value fordepth_limitwhen we call the function, the specified value will be used instead of-1.This function header also specifies a default value of
Nonefor the heuristic, which is why this input is optional. If we leave it out when we call the function, we will use the default value ofNone. If we specify aheuristicin the function call, we will use thatheuristicfunction.Your function should open the file with the specified
filenamefor reading, and it should use a loop to process the file one line at a time. We discussed line-by-line file processing earlier in the semester, and you wrote a related function for an earlier problem set.For each line of the file, the function should:
-
obtain the digit string on that line (stripping off the newline at the end of the line)
-
take the steps needed to solve the eight puzzle for that digit string using the algorithm specified by the second input to the function
-
report the number of moves in the solution, and the number of states tested during the search for a solution
In addition, the function should perform the cumulative computations needed to report the following summary statistics after processing the entire file:
- number of puzzles solved
- average number of moves in the solutions
- average number of states tested
For example:
>>> process_file('10_moves.txt', 'BFS') 125637084: 10 moves, 661 states tested 432601785: 10 moves, 1172 states tested 025318467: 10 moves, 534 states tested 134602785: 10 moves, 728 states tested 341762085: 10 moves, 578 states tested 125608437: 10 moves, 827 states tested 540132678: 10 moves, 822 states tested 174382650: 10 moves, 692 states tested 154328067: 10 moves, 801 states tested 245108367: 10 moves, 659 states tested solved 10 puzzles averages: 10.0 moves, 747.4 states tested
(In this case, because BFS finds optimal solutions, every solution has the same number of moves, but for other algorithms this won’t necessarily be the case.)
Notes/hints:
-
You can model your code for solving a given puzzle on the code that we’ve given you in the
eight_puzzledriver function. In particular, you can emulate the way that this function:- creates
BoardandStateobjects for the initial state - calls the
create_searcherhelper function to create the necessary type of searcher object, and handles the possible return value ofNonefrom that function
- creates
-
When calling the searcher object’s
find_solutionmethod, you should do so as follows:soln = None try: soln = searcher.find_solution(s) except KeyboardInterrupt: print('search terminated, ', end='')
Making the call to
find_solution(s)in this way will allow you to terminate a search that goes on too long by using Ctrl-C. In such cases,solnwill end up with a value ofNone(meaning that no solution was found), and you should make sure to properly handle such cases. -
You should not use a timer in this function.
-
This function should not return a value.
Testing your function:
-
If you haven’t already done so, download the 10_moves.txt file, putting it in the same folder as the rest of your files for the eight puzzle.
-
Try to reproduce the results for BFS shown above.
-
Try applying Greedy Search to the same file. You may find that it takes Greedy a very long time to solve some of the puzzles, at least when using the num-misplaced-tiles heuristic. If this happens, use Ctrl-C as needed to terminate the problematic searches. When we processed
10_moves.txtusing our implementation of Greedy, we ended up using Ctrl-C to terminate two of the searches:>>> process_file('10_moves.txt', 'Greedy', -1, h1) 125637084: 204 moves, 658 states tested 432601785: 12 moves, 13 states tested 025318467: search terminated, no solution 134602785: 78 moves, 221 states tested 341762085: 26 moves, 339 states tested 125608437: 162 moves, 560 states tested 540132678: 68 moves, 749 states tested 174382650: search terminated, no solution 154328067: 10 moves, 16 states tested 245108367: 48 moves, 49 states tested solved 8 puzzles averages: 76.0 moves, 325.625 states tested
-
It’s also possible for none of the puzzles to have a solution, and you should handle that situation appropriately. For example, this can happen if you impose a depth limit that is too small:
>>> process_file('10_moves.txt', 'DFS', 5) # depth limit of 5 125637084: no solution 432601785: no solution 025318467: no solution 134602785: no solution 341762085: no solution 125608437: no solution 540132678: no solution 174382650: no solution 154328067: no solution 245108367: no solution solved 0 puzzles
Note that you can’t compute any averages in this case, so you shouldn’t print the
averagesline in the results.
-
-
Create a Jupyter Notebook named
eightpuzzle.ipynb, and put your name and email (and those of your partner, if any) at the top of the file. -
Conduct an initial set of experiments in which you try all of the algorithms on the puzzles in the following files:
- 5_moves.txt - puzzles that can be solved in 5 moves
- 10_moves.txt - puzzles that can be solved in 10 moves
- 15_moves.txt - puzzles that can be solved in 15 moves
More specifically, you should run the following algorithms on each file:
- random
- BFS
- DFS with a depth limit of 20
- DFS with a depth limit of 50
- Greedy (using the default, num-misplaced-tiles heuristic)
- A* (using the same heuristic)
Note that it may be necessary to use Ctrl-C to terminate searches that take too much time. You might want to pick a given amount of time (e.g., 30 seconds or 1 minute), and use Ctrl-C to terminate any search that doesn’t complete in that time.
In your Jupyter Notebook, create three tables that summarize the results of these initial experiments. Use a separate table for each file’s results. For example, the results for
5_moves.txtshould be put into a table like this:puzzles with 5-move optimal solutions ------------------------------------- algorithm num. solved avg. moves avg. states tested ---------------------------------------------------------------------- random BFS DFS (depth limit 20) DFS (depth limit 50) Greedy Search A*
Use Matplotlib to create a visualization showing and comparing these results. The specific format of the plot is up to you (e.g. bar graph, colors, labels, etc). You are encouraged to find a sample graph in the Matplotlib examples or tutorials and modify it as long as you cite the source of any code you use or modify.
Below these tables and graphs, write a short reflection (one or two paragraphs) in which you summarize the key points that are illustrated by the results. For example, you might discuss whether the algorithms produce reliably optimal results, and how much work they do in finding a solution. There’s no one correct reflection; we just want to see that you have reflected intelligently on the results and drawn some conclusions.
-
Even informed search algorithms like Greedy Search and A* can be slow on problems that require a large number of moves. This is especially true if the heuristic function used by the algorithm doesn’t do a good enough job of estimating the remaining cost to the goal.
Our default heuristic–which uses the number of misplaced tiles as the estimate of the remaining cost–is one example of a less than ideal heuristic. For example, consider the following two puzzles:
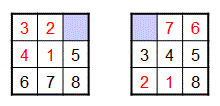
Both of them have 4 misplaced tiles (the ones displayed in red), but the puzzle on the left can be solved in 4 moves, whereas the puzzle on the right requires 24 moves! Clearly, it would be better if our heuristic could do a better job of distinguishing between these two puzzles.
Come up with at least one alternate heuristic, and use it in your
GreedySearcherorAStarSearcherobjects.To do so, you should take the following steps:
-
Define a function (e.g.,
h1(state)orh2(state)) in yoursearcher.pyfile. This function will take aStateobject as a parameter, and return a heuristic value (i.e., a number). -
To use this function as your heuristic, you will pass it into the constructor for
GreedySearcherorAStarSearcherobjects. For example:>>> g = GreedySearcher(-1, h1) # no depth limit, basic heuristic
where
h1is the heuristic function to use, and-1is the depth limitWhen using the
eight_puzzledriver function or theprocess_filefunction that you wrote earlier, you should specify the heuristic number as the third input. For example:>>> process_file('15_moves.txt', 'A*', -1, h1) # no depth limit, basic heuristic
You are welcome to design more than one new heuristic function, although only one is required. Give each heuristic its own integer so that you can choose between them.
When testing and refining your heuristic(s), you can use the files that we provided above, as well as the following files:
- 18_moves.txt - puzzles that can be solved in 18 moves
- 21_moves.txt - puzzles that can be solved in 21 moves
- 24_moves.txt - puzzles that can be solved in 24 moves
- 27_moves.txt - puzzles that can be solved in 27 moves
Compare the performance of Greedy and A* using the default heuristic to their performance using your new heuristic(s). Keep revising your heuristic(s) as needed until you are satisfied. Ideally, you should see the following when using your new heuristic(s):
- Both algorithms are able to solve puzzles more quickly – testing fewer states on average and requiring fewer searches to be terminated.
- Greedy Search is able to find solutions requiring fewer moves.
- A* continues to find optimal solutions. (If it starts finding solutions with more than the optimal number of moves, that probably means that your heuristic is overestimating the remaining cost for at least some states.)
-
-
Although you are welcome to keep more than one new heuristic function, we will ultimately test only one of them. Please adjust your code as needed so that the heuristic that you want us to test is identified using the name
h2. Also, please make sure that we will still be able to test the default, num-misplaced-tiles heuristic if we specify a value ofh1for the heuristic.In your Jupyter Notebook, briefly describe how your best new heuristic works:
heuristic 1 ----------- This heuristic ...
If your code includes other alternate heuristics, you are welcome to describe them as well, although doing so is not required.
-
Conduct a second set of experiments in which you try both your new heuristic(s) and the default heuristic on the puzzles in the four new files provided above (the ones that require 18, 21, 24, and 27 moves).
In your Jupyter Notebook, create four tables that summarize the results of these experiments. Use a separate table for each file’s results. For example, the results for
18_moves.txtshould be put into a table like this:puzzles with 18-move optimal solutions -------------------------------------- algorithm num. solved avg. moves avg. states tested ---------------------------------------------------------------------- Greedy (heuristic h1) Greedy (heuristic h2) # Greedy with any other heuristics A* (heuristic h1) A* (heuristic h2) # Greedy with any other heuristics
As before, create plots or graphs using Matplotlib to visualize these results.
Below these tables, write a short reflection (one or two paragraphs) in which you summarize the key points that are illustrated by the results. Here again, there is no one correct reflection; we just want to see that you have reflected intelligently on the results and drawn some conclusions.
Submitting Your Work
The following instructions are for submitting just the Jupyter Notebook report. Please submit the final Python code in PS19.
You should use Gradescope to submit the following files under PS20:
- your
eightpuzzle.ipynbfile containing the results of your experiments - your
eightpuzzle.pdf- a PDF version of the Jupyter Notebook (please ensure images and plots are visible).
Warnings
-
Make sure to use these exact file names, or Gradescope will not accept your files. If Gradescope reports that a file does not have the correct name, you should rename the file using the name listed in the assignment or on the Gradescope upload page.
-
If you make any last-minute changes to one of your Python files (e.g., adding additional comments), you should run the file in VS Code after you make the changes to ensure that it still runs correctly. Even seemingly minor changes can cause your code to become unrunnable.
-
If you submit an unrunnable file, Gradescope will accept your file, but it will not be able to auto-grade it. If time permits, you are strongly encouraged to fix your file and resubmit. Otherwise, your code will fail most if not all of our tests.